UNC Researchers Present VideoDirectorGPT: Using AI to Generate Multi-Scene Videos from Text
The key innovation proposed is decomposing multi-scene video generation into two steps: a director step and a "film" step.


Generating video content automatically from text descriptions has been an elusive goal for artificial intelligence. While recent progress has enabled users to create short video clips from text prompts, generating long, detailed videos containing multiple scenes with smooth transitions remains extremely challenging for AI systems.
Subscribe or follow me on Twitter for more content like this!
In a new paper (Github page here) published just a few days ago, researchers from the University of North Carolina Chapel Hill propose an innovative two-stage framework called VIDEODIRECTORGPT that pushes the boundaries of coherent multi-scene video generation capabilities for AI. Their technique demonstrates substantially improved control over object layouts, motion, and consistency across scenes compared to prior state-of-the-art text-to-video models.
Why Multi-Scene Video Generation Matters
Being able to automatically create videos spanning diverse events and multiple scenes from text would open up many exciting applications. For instance, generating detailed visualizations from conceptual descriptions, automated production of educational video tutorials, summarizing lengthy footage into abridged coherent videos, and assisting content creators with rough video outlines.
However, these applications require AI not just to fabricate short video clips, but also realistically transition across multiple scenes with appropriate background, layout, and continuity of objects. For example, consider generating a video tutorial from the text "First add flour, then crack eggs and mix wet ingredients. Finally, pour the batter into a cake pan." This requires recognizing the multiple steps, arranging the scenes accordingly, maintaining consistency of ingredients and utensils across the scenes, and smoothly connecting the actions.
Multi-scene video generation with conceptual and visual coherence poses some unique challenges beyond single-scene text-to-video generation:
The AI model must comprehend the high-level semantics and breakdown of diverse multi-step events from limited text.
Layout, scale, counts, and spatial relationships of objects must be accurately controlled across potentially complex scene compositions.
Characters and other elements must have visual consistency when appearing across multiple scenes.
A variety of backgrounds, camera movements, and transitions may be needed between distinct but related events.
VIDEODIRECTORGPT proposes an innovative approach attempting to overcome these challenges by combining the powers of large language models and controllable generative video models. Let's see how it works!
Inside VIDEODIRECTORGPT: A Two-Stage Framework
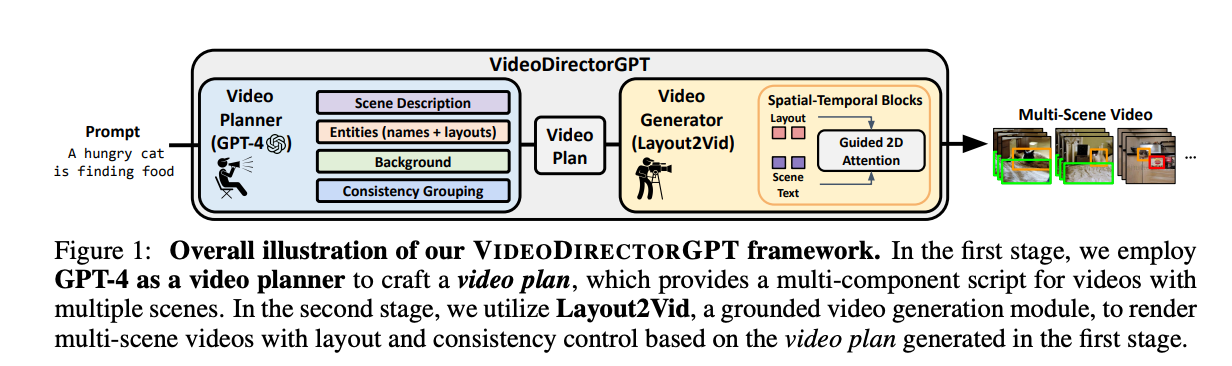
How VIDEODIRECTORGPT works - from the paper.
VIDEODIRECTORGPT consists of two key modules working in tandem:
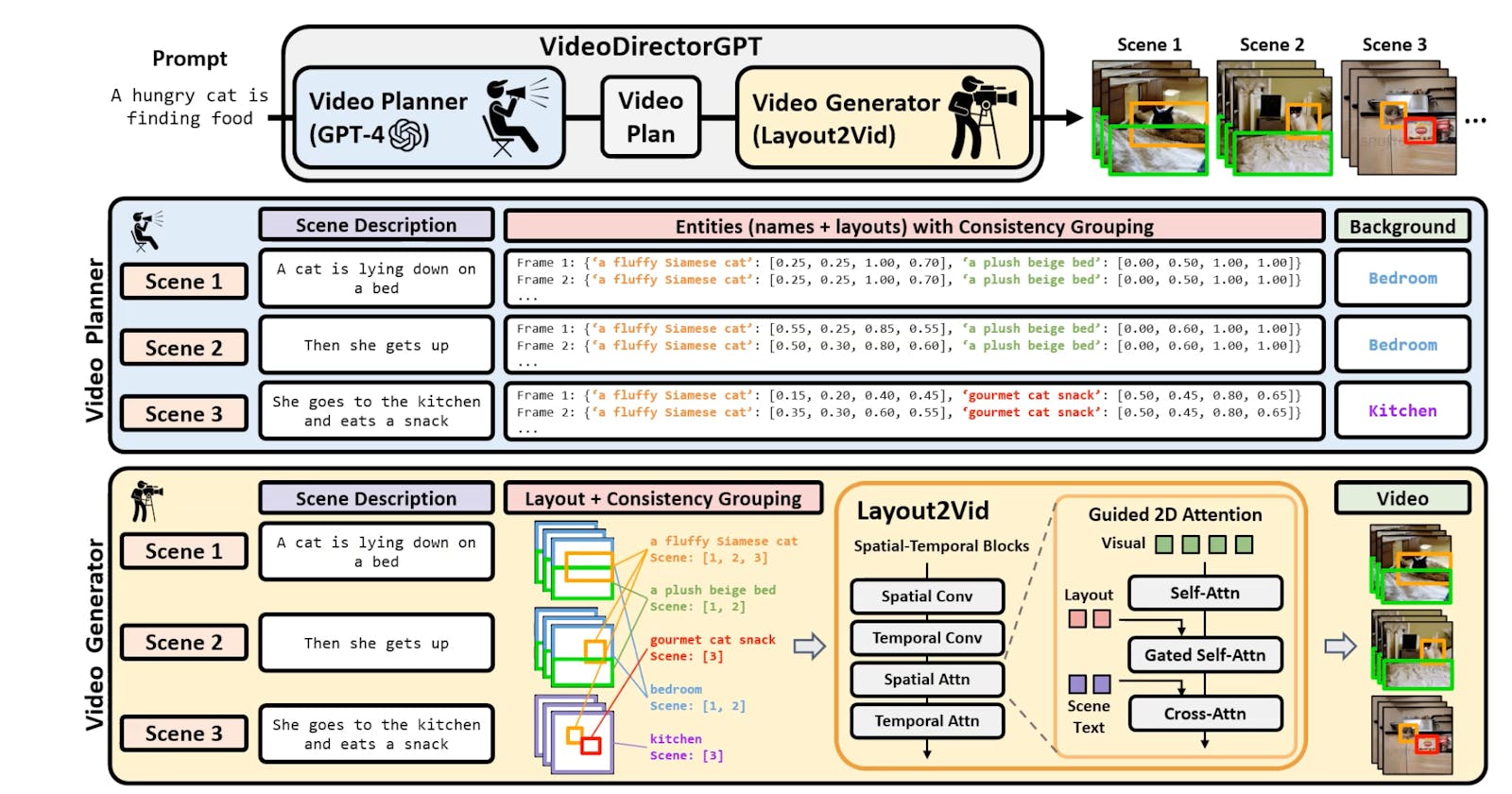
Video Planner: This module uses the cutting-edge GPT-4 language model to take a text prompt and expand it into a structured "video plan". This video plan contains multiple critical components for guiding the video generation process:
Multi-scene textual descriptions elaborating the diverse events and actions within the video
Lists of entities (objects, characters, etc) that should appear in each scene
Layouts specifying the location and bounding boxes of entities in each frame
Background descriptions for each scene setting
Consistency groupings indicating which entities reappear across multiple scenes
By leveraging the vast knowledge encapsulated within GPT-4, the video planner is able to take even a simple starting text prompt and flesh out a comprehensive video blueprint to facilitate generating a smooth, realistic video.
Video Generator (Layout2Vid): This module takes the structured video plan from the first stage and generates the actual multi-scene video. Layout2Vid builds upon ModelScopeT2V, a state-of-the-art text-to-video model, enhancing it with customizations for controlled spatial layouts and cross-scene consistency guided by the video plan.
Key innovations enable Layout2Vid to achieve better object layout and movement direction compared to prior text-to-video models while also improving visual coherence across scenes:
Spatial layout control is added through a custom "Guided 2D Attention" mechanism that modulates the generation process based on bounding box locations.
Training only the layout control components on image datasets rather than expensive video data.
Representing entities consistently across scenes using shared image+text embeddings.
Adjusting the ratio of layout-guided vs free generation steps.
Together, the video planner and video generator stages aim to take maximal advantage of recent advances in both language and video generation models to surpass the limitations of previous methods.
Results: Smoother Object Control and Scene Consistency
Comprehensive experiments demonstrate the advantages of the VIDEODIRECTORGPT approach on both control of single-scene videos as well as coherence across multi-scene videos:
Single scene video control: On the VPEval benchmark measuring layout accuracy, VIDEODIRECTORGPT substantially outperforms baselines like ModelScopeT2V on object counts, spatial relationships, and scale. It also shows significantly improved object movement direction over baselines on an "ActionBench-Direction" benchmark. This indicates the video planner's layout and motion descriptions provide useful guidance to Layout2Vid.
Multi-scene consistency: On a variety of multi-scene video datasets, VIDEODIRECTORGPT produces noticeably higher object consistency across scenes compared to baselines. Human evaluations also prefer the visual quality, text alignment, and object continuity of videos produced by VIDEODIRECTORGPT.
Overall video fidelity: Despite the additional control constraints, VIDEODIRECTORGPT maintains high visual quality and text-video alignment on open-domain video generation benchmarks like MSR-VTT, competitive with leading text-to-video models.
These results highlight the promise of this two-stage framework combining planning with a large language model and controlled generation with Layout2Vid. The improved layout, motion, and cross-scene consistency open up the potential for diverse applications requiring coherent multi-scene video generation from text.
Limitations and Impact
While VIDEODIRECTORGPT makes notable progress on multi-scene video generation, there remain some challenges and limitations to address in future work:
Generated videos still contain glitches and artifacts. Visual quality trails behind recent image generation quality.
The diversity of possible backgrounds, camera motions, transitions, and entities remains limited compared to real-world complexity.
Errors can accumulate across stages, especially if the video planner produces imperfect descriptions or layouts.
Long 5+ minute videos with dozens of complex scenes have not been demonstrated.
As with any generative AI system, there exists potential for misuse of synthesized video. Careful policies should govern acceptable use cases and clarify synthetic content to avoid deception. If harnessed responsibly, technology like VIDEODIRECTORGPT could help democratize video creation and provide visual aids to complement textual information.
My Thoughts/Questions
Looking at the results, VIDEODIRECTORGPT does appear to provide substantial improvements in object control and cross-scene consistency compared to baseline text-to-video models. But, I still have many open questions about the limits of this approach.
The paper focuses on relatively short and simple multi-scene videos. I'm curious how it would fare on long, elaborate 5-10-minute videos (that you would post on Youtube). Also, while visual coherence is improved, the overall fidelity still seems to trail behind text-to-image generation quality. And it's unclear how robust VIDEODIRECTORGPT is to imperfect video plans.
Still, given the challenges, these results seem interesting as an initial proof of concept.
Cautiously Excited for the Future
Stepping back, I find VIDEODIRECTORGPT to showcase promising innovation and directionally correct progress on an extremely challenging problem. The two-stage formulation and controlled generation approach appears to improve over prior text-to-video methods.
Of course, there is still a very long way to go before we see AI reliably generating detailed, multi-scene videos on par with human creators. But papers like this get me cautiously excited for a future where automatic video generation can surpass today's limitations and unlock new applications we can only imagine right now. I'll be keeping a close eye as researchers continue to iterate and build upon these ideas!
Subscribe or follow me on Twitter for more content like this!