T-FREE: Tokenizer-Free Generative LLMs via Sparse Representations for Memory-Efficient Embeddings


This is a Plain English Papers summary of a research paper called T-FREE: Tokenizer-Free Generative LLMs via Sparse Representations for Memory-Efficient Embeddings. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- The paper introduces T-FREE, a new approach to building large language models (LLMs) that does not rely on traditional tokenization.
- T-FREE uses sparse representations to create memory-efficient embeddings, which can reduce the memory footprint of LLMs.
- The proposed method aims to address the limitations of classic tokenization approaches, which can be computationally expensive and may not capture the full semantic context of language.
Plain English Explanation
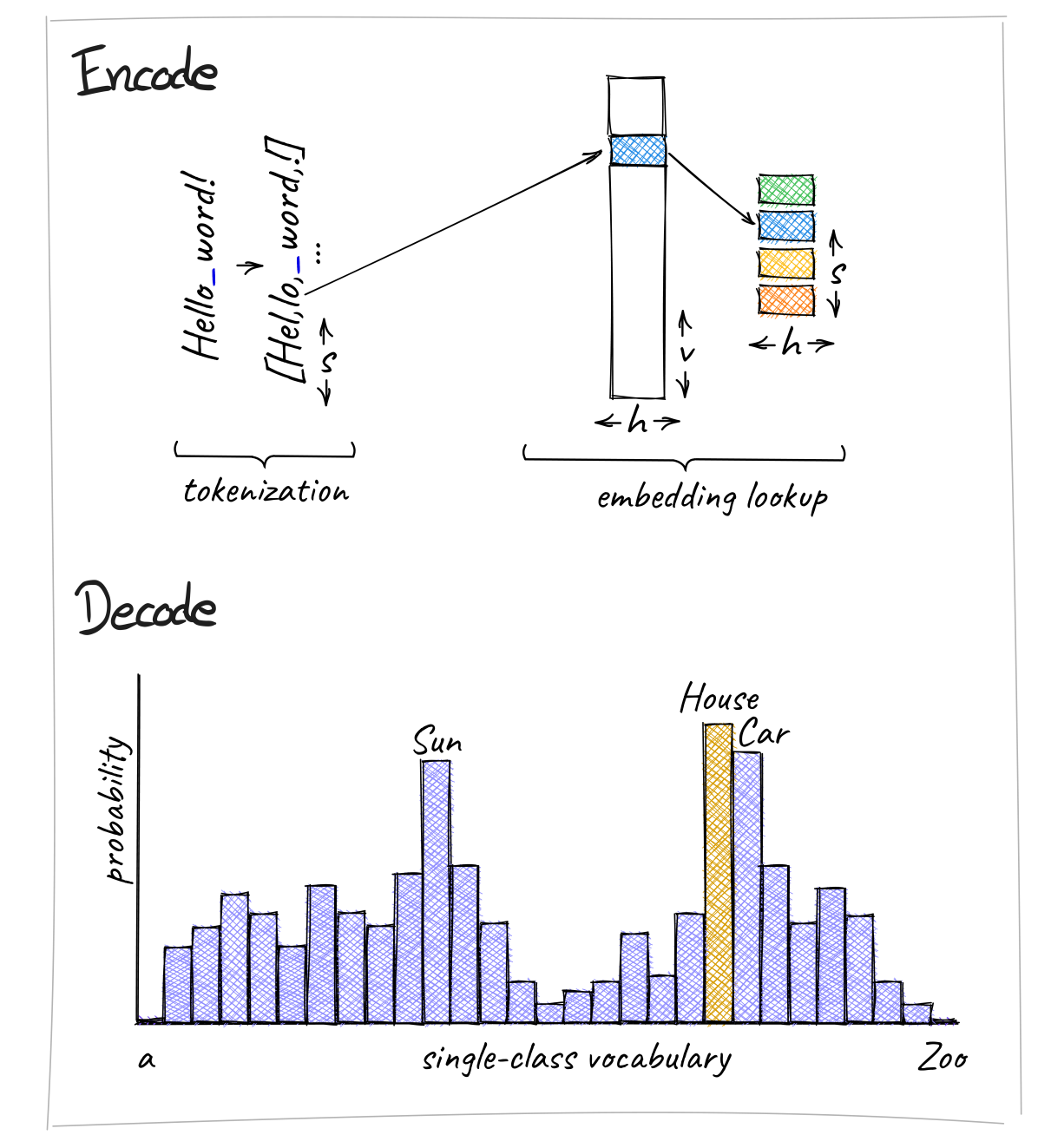
The paper proposes a new way to build large language models (LLMs) that doesn't use traditional tokenization. Tokenization is a common technique in natural language processing where text is broken down into smaller units, like words or phrases, that a machine can understand. However, this process can be computationally expensive and may not fully capture the meaning of language.
T-FREE, the approach introduced in this paper, uses a different strategy called "sparse representations" to create efficient embeddings, which are mathematical representations of language. These embeddings can capture the meaning of text while using less memory than traditional methods. This could make it easier to build and deploy large language models, which are AI systems that can understand and generate human-like text.
The key idea behind T-FREE is to avoid the traditional tokenization step and instead represent text as a sparse vector, where most of the elements are zero. This sparse representation can be more efficient in terms of memory usage, while still preserving the essential semantic information in the text.
The paper presents technical details on how T-FREE works and compares its performance to other language modeling approaches. The goal is to develop a more memory-efficient way to build powerful language models that can be used in a wide range of applications, from natural language processing to text generation.
Technical Explanation
The paper introduces T-FREE, a novel approach to building large language models (LLMs) that avoids the use of traditional tokenization. Instead, T-FREE relies on sparse representations to create memory-efficient embeddings for text.
Traditionally, LLMs have relied on tokenization, where text is broken down into smaller units (e.g., words, subwords) that can be processed by the model. However, this tokenization process can be computationally expensive and may not fully capture the semantic context of language. T-FREE addresses these limitations by using a tokenizer-free approach to language modeling.
The key idea behind T-FREE is to represent text as a sparse vector, where most of the elements are zero. This sparse representation can be more memory-efficient than traditional dense embeddings, while still preserving the essential semantic information in the text. The paper introduces a novel training procedure to learn these sparse representations directly from text, without the need for a separate tokenization step.
The authors also explore zero-shot tokenizer transfer, where the sparse representations learned by T-FREE can be used to initialize other language models, potentially improving their performance and reducing the need for resource-intensive tokenization.
Additionally, the paper investigates multi-word tokenization as a way to further optimize the memory usage of the sparse representations, by encoding longer semantic units as single tokens.
Critical Analysis
The T-FREE approach presented in the paper offers a promising solution to the limitations of traditional tokenization in large language models. By using sparse representations, the model can achieve memory efficiency without sacrificing the ability to capture the semantic context of language.
One potential limitation of the approach is that the training procedure for learning the sparse representations may be more complex or computationally intensive than traditional tokenization methods. The paper does not provide a detailed comparison of the training time or resource requirements of T-FREE compared to other approaches.
Additionally, while the paper demonstrates the effectiveness of T-FREE on several benchmark tasks, it would be valuable to see how the model performs on a wider range of real-world applications, particularly those that require handling of diverse language domains or specialized vocabularies.
Finally, the paper does not address potential issues related to the interpretability or explainability of the sparse representations learned by T-FREE. As language models become more complex, it is important to understand the internal workings of the models and how they arrive at their outputs.
Overall, the T-FREE approach represents an interesting and innovative solution to the challenges of building memory-efficient large language models. Further research and development in this area could lead to significant advancements in natural language processing and generation.
Conclusion
The T-FREE paper introduces a novel approach to building large language models that avoids the use of traditional tokenization. By using sparse representations to create memory-efficient embeddings, T-FREE aims to address the limitations of classic tokenization methods, which can be computationally expensive and may not fully capture the semantic context of language.
The key innovation of T-FREE is its ability to learn these sparse representations directly from text, without the need for a separate tokenization step. This could lead to more efficient and effective language models that can be deployed in a wide range of applications, from natural language processing to text generation.
While the paper presents promising results, there are still some open questions and areas for further research, such as the training complexity of the approach, its performance on diverse real-world tasks, and the interpretability of the learned sparse representations. Nonetheless, the T-FREE approach represents an exciting step forward in the development of memory-efficient and powerful large language models.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.