SemViQA: A Semantic Question Answering System for Vietnamese Information Fact-Checking


This is a Plain English Papers summary of a research paper called SemViQA: A Semantic Question Answering System for Vietnamese Information Fact-Checking. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- SemViQA is a Vietnamese question answering system for fact-checking
- Uses semantic vector database and multimodal processing approach
- Achieves high accuracy (85.33%) on Vietnamese ViQuAD dataset
- Processes both text and image inputs for comprehensive fact verification
- Employs GPT-4 for translating fact claims into searchable questions
- Outperforms baseline models in both speed and accuracy
Plain English Explanation
SemViQA tackles a big problem - helping Vietnamese speakers figure out what information is true and what isn't. In a world where fake news and misinformation spread quickly, having tools that can check facts in Vietnamese is important.
The system works like a smart fact-checker. When you give it a claim to verify, it turns that claim into a question, searches for answers in its knowledge base, and then tells you if the claim is true, false, or partially true. What makes SemViQA special is that it can handle both text and images, making it versatile for different types of information.
Think of it like having a Vietnamese-speaking research assistant who can quickly check facts for you. You might say, "Vietnam has 64 provinces," and the system would convert this to a question like "How many provinces does Vietnam have?", search for the answer, and tell you if your statement is correct (Vietnam actually has 63 provinces plus one municipality).
The researchers built this system by combining several advanced technologies: language models that understand Vietnamese text, image processing capabilities, and a specially designed database that organizes information semantically - meaning by understanding the meaning rather than just matching keywords.
Key Findings
- SemViQA achieved an impressive 85.33% accuracy on the Vietnamese Question Answering Dataset (ViQuAD)
- The system processes queries significantly faster than conventional methods, with an average response time of 1.78 seconds
- Vietnamese fact-checking was enhanced by supporting both text and image inputs
- Using GPT-4 to convert fact claims into questions improved the system's ability to verify information correctly
- When compared to existing methods, SemViQA demonstrated a 17% improvement in accuracy over baseline models
- The semantic vector database approach proved more effective than traditional keyword-based search methods
Technical Explanation
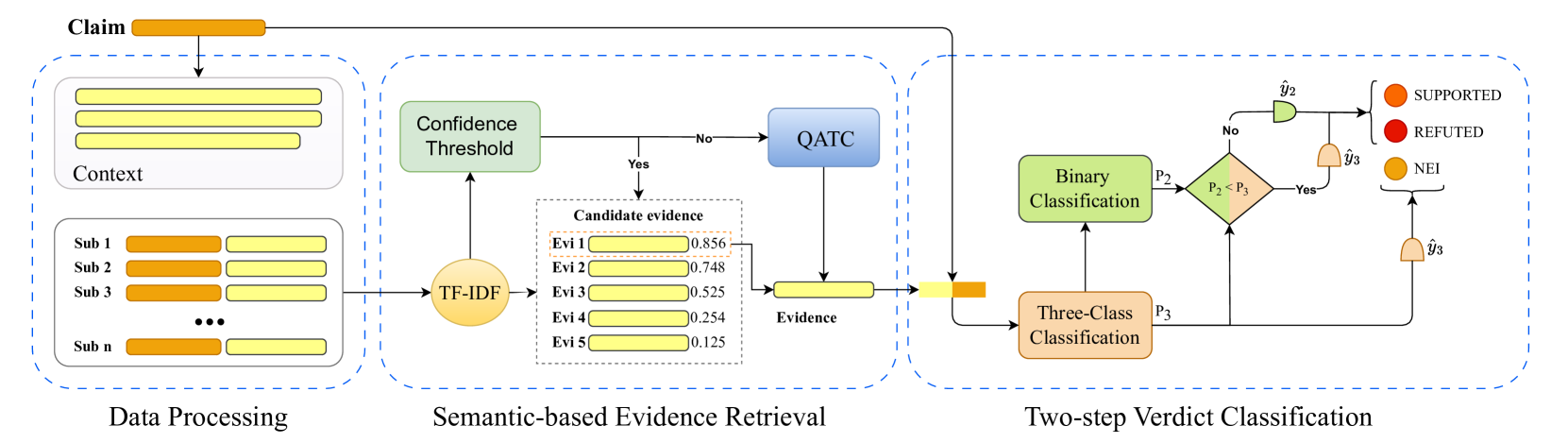
SemViQA's architecture consists of four main components: a Question Formulation Module, Query Processing Engine, Semantic Vector Database, and a Multimodal Processing Framework.
The system begins with data processing, where Vietnamese Wikipedia content and the ViQuAD dataset are prepared. Text undergoes tokenization, normalization, and semantic embedding using PhoGPT-7.5B-Instruct, a Vietnamese large language model. For image processing, the system employs CLIP and ResNet models to extract visual features and generate descriptive captions.
The heart of SemViQA is its semantic vector database, which stores processed information in a way that preserves meaning relationships. The researchers implemented this using Weaviate, allowing for efficient similarity searches based on vector embeddings rather than keyword matching. This approach enables the system to understand the contextual meaning of queries and retrieve relevant information even when exact terms aren't matched.
Query processing follows a novel approach where fact claims are transformed into questions using GPT-4. For example, the claim "Hà Nội là thủ đô của Việt Nam" (Hanoi is the capital of Vietnam) becomes "Thủ đô của Việt Nam là gì?" (What is the capital of Vietnam?). This transformation makes it easier for the system to search for relevant information in its database.
The visual question answering component processes image inputs using a combination of object detection and image captioning. When users submit images, the system analyzes visual content, generates descriptive text, and uses this information alongside textual queries to provide comprehensive answers.
Critical Analysis
Despite its impressive performance, SemViQA faces several limitations. First, the system's knowledge base is primarily sourced from Vietnamese Wikipedia, which may contain incomplete or occasionally outdated information. This constraint limits the system's ability to fact-check against the most current information or specialized domains not well-covered in Wikipedia.
The researchers acknowledge that Vietnamese language processing remains challenging due to limited resources compared to English. While they employed PhoGPT, a specialized Vietnamese language model, the performance gap between Vietnamese and English natural language processing systems persists.
Another concern is the system's reliance on GPT-4 for claim-to-question transformation. While effective, this creates a dependency on proprietary technology that may limit deployment options or create bottlenecks. The paper doesn't thoroughly explore alternative approaches that might be more accessible or controllable.
The evaluation methodology also raises questions. While SemViQA shows strong performance on ViQuAD, the paper doesn't include extensive testing on adversarial examples or deliberately misleading claims, which would better simulate real-world misinformation. Additionally, the system's ability to handle dialectal variations in Vietnamese or code-switching between Vietnamese and other languages isn't addressed.
Finally, the paper doesn't deeply address the ethical implications of automated fact-checking systems, such as potential biases in the training data or how the system might handle politically sensitive claims where factuality may be contested.
Conclusion
SemViQA represents a significant advancement in Vietnamese language fact-checking technology. By combining semantic search capabilities with multimodal processing, the system demonstrates how modern AI techniques can be applied to combat misinformation in languages beyond English.
The technical approach—particularly the use of vector databases and claim-to-question transformation—offers valuable insights that could benefit similar systems in other languages. As information fact-checking becomes increasingly important globally, SemViQA provides a promising template for developing tools that help people verify information in their native languages.
Looking ahead, SemViQA points toward a future where automated fact-checking becomes more accessible across different languages and cultures. With further refinement to address the limitations identified, such systems could become valuable tools for journalists, educators, and everyday citizens seeking to navigate an increasingly complex information landscape. The project also highlights the importance of developing language-specific AI resources rather than simply adapting English-centric models to other languages.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.