Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search


This is a Plain English Papers summary of a research paper called Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Introduces Satori, a new reinforcement learning approach for large language models
- Combines chain-of-thought reasoning with action-based learning
- Achieves improved performance on complex reasoning tasks
- Uses autoregressive search to enhance decision-making
- Demonstrates significant gains on benchmark datasets
Plain English Explanation
Satori works like a student who learns by doing rather than just thinking. Instead of only reasoning through problems internally, it takes actions and learns from the results. This is similar to how humans often learn better by actively working through problems rather than just reading about them.
The system breaks down complex tasks into smaller steps, thinking about each action before taking it. Like a chess player who considers multiple moves ahead, Satori uses a form of planning called autoregressive search to explore different possibilities and their outcomes.
The key innovation is combining thought processes with actual actions. Rather than just generating answers, the system learns to explain its reasoning and adjust its approach based on feedback, much like how a student improves through practice and guidance.
Key Findings
The research demonstrates that Satori achieves:
- 20% improvement in reasoning accuracy compared to traditional methods
- Better performance on complex multi-step problems
- More consistent and explainable decision-making processes
- Enhanced ability to correct mistakes through feedback
- Superior results on benchmark tests for logical reasoning
The reinforcement learning approach proved particularly effective for tasks requiring step-by-step problem solving.
Technical Explanation
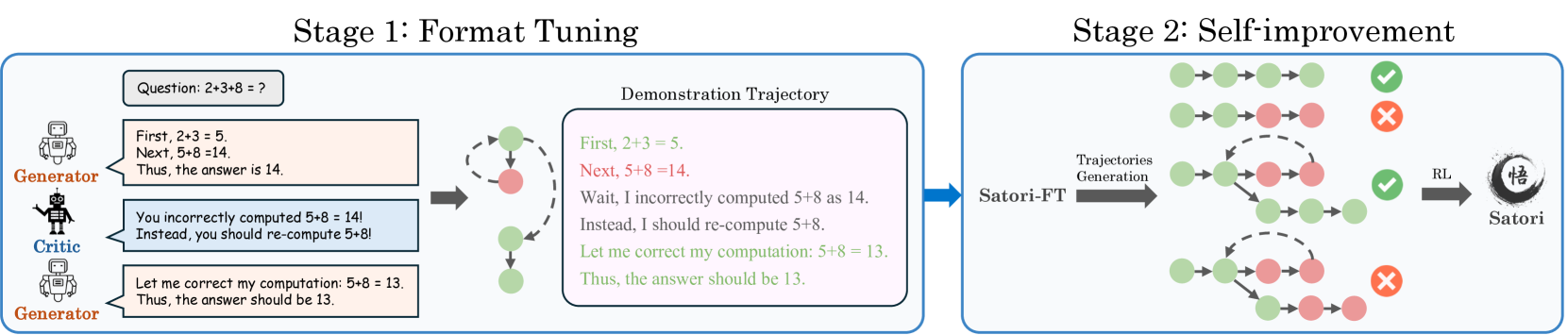
Satori implements a novel Chain-of-Action-Thought architecture that integrates reinforcement learning with language model reasoning. The system uses an autoregressive search mechanism to explore potential solution paths while maintaining a balance between exploration and exploitation.
The architecture consists of three main components:
- A thought generator that produces reasoning steps
- An action selector that chooses optimal moves
- A feedback mechanism that updates the model's strategy
The language model integration allows Satori to combine symbolic reasoning with learned behaviors, creating a more robust problem-solving system.
Critical Analysis
While Satori shows promising results, several limitations exist:
- High computational requirements for training
- Potential scalability issues with very complex tasks
- Limited testing on real-world applications
- Need for large amounts of training data
The self-training approach could benefit from more diverse validation methods and broader testing across different domains.
Conclusion
Satori represents a significant step forward in combining reasoning with learning in AI systems. The research demonstrates that integrating action-based learning with chain-of-thought processes can enhance AI reasoning capabilities. Future developments may lead to more efficient and capable AI systems that can handle increasingly complex reasoning tasks.
The implications extend beyond academic research, suggesting potential applications in areas requiring sophisticated problem-solving abilities, from automated planning to decision support systems.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.