

This is a Plain English Papers summary of a research paper called Process-based Self-Rewarding Language Models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Process-based Self-Rewarding Language Models (PReSRM) introduces a new self-improvement technique for AI systems
- Focuses on evaluating reasoning processes rather than just final answers
- Combines process-guided generation with self-rewarding mechanisms
- Shows significant improvements on mathematical reasoning and planning tasks
- Outperforms traditional RLHF methods while being more efficient
- Achieves up to 31.6% improvement on challenging GSM8K math problems
Plain English Explanation
AI models have gotten pretty good at giving answers, but they still struggle with complex reasoning. It's like having a student who can get the right answer but can't explain how they got there.
Current methods for improving AI focus on rewarding the final answer rather than the thinking process. Process-based self-rewarding changes this approach entirely.
Think of it like teaching a child math. Instead of just checking if their final answer is correct, you'd want to see their work. You'd reward them for using good problem-solving steps, even if they make small calculation errors along the way. This is exactly what PReSRM does with AI models.
The researchers created a system where the AI evaluates its own reasoning process. It doesn't just look at its final answer, but examines the step-by-step thinking that led to that answer. The AI then rewards itself when it uses good reasoning strategies, helping it learn to think more clearly.
This approach makes a big difference in practice. When tested on math problems and planning tasks, the AI improved dramatically - solving up to 31.6% more problems correctly on a challenging math dataset.
Key Findings
- PReSRM significantly outperforms traditional reinforcement learning from human feedback (RLHF) methods, achieving state-of-the-art results on the GSM8K benchmark
- The system showed a 31.6% improvement on GSM8K accuracy without using any external data
- Process-based evaluation correlates better with human judgment than outcome-based evaluation
- The approach is computational efficient, requiring less training time than traditional methods
- PReSRM produces more coherent, structured reasoning patterns compared to baseline models
- The technique transfers successfully across different types of reasoning tasks, including mathematical reasoning and planning problems
- Self-rewarding models can effectively distinguish between good and poor reasoning processes
Technical Explanation
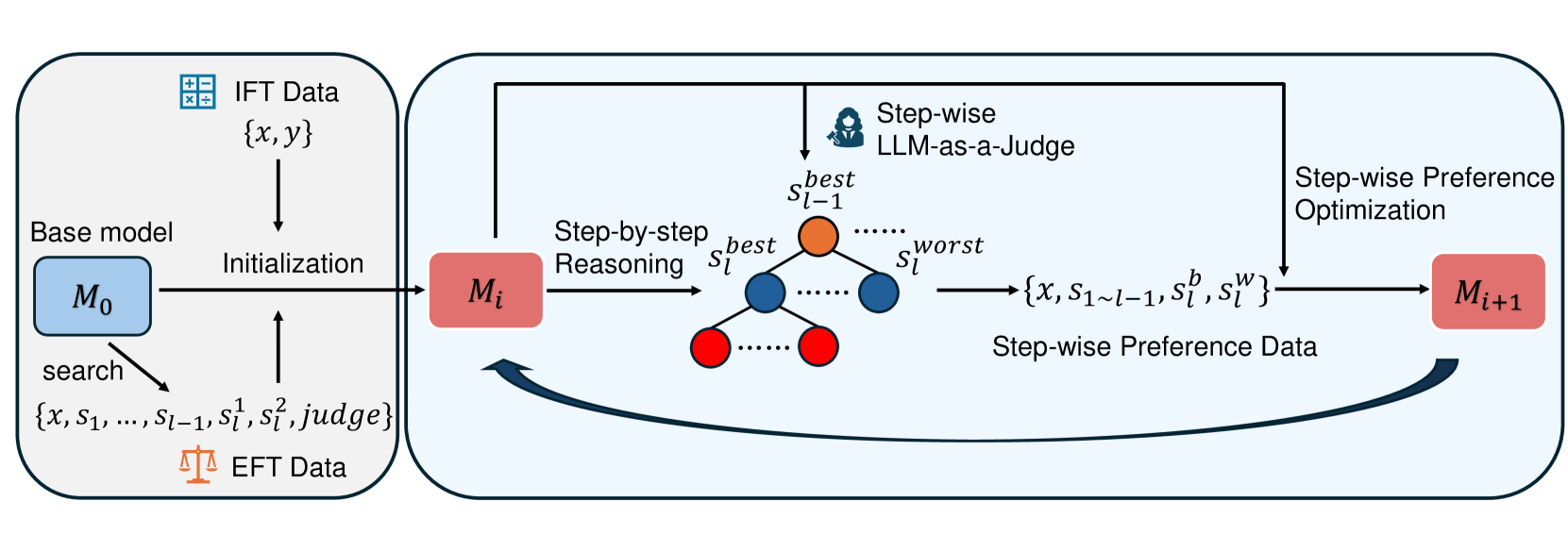
The PReSRM framework consists of four main components: sampling multiple reasoning paths, evaluating these paths based on the reasoning process, providing rewards based on this evaluation, and updating the model using these rewards.
The system starts by generating multiple reasoning attempts for a given problem. Each attempt contains a step-by-step solution path. The innovation comes in the evaluation phase - instead of just checking if the final answer is correct, the model examines the quality of the reasoning process itself.
For mathematical reasoning problems, the researchers implemented specific evaluation criteria focused on logical coherence, correct application of mathematical principles, and systematic problem-solving. The reward function prioritizes sound reasoning even when the final answer contains minor errors.
The researchers used the LLama2-7B model as the base architecture and compared against several baselines including vanilla LLama2, RLHF-tuned models, and other self-improvement techniques. Training involved standard reinforcement learning techniques based on the KL-regularized PPO algorithm.
One particularly interesting aspect was the creation of a "pseudo-human preference dataset" where the model generated and evaluated reasoning pairs. This approach allowed for self-improving alignment without requiring extensive human annotation.
The results show that process-based rewards substantially outperform outcome-based rewards, particularly on complex reasoning tasks. The GSM8K results (jumping from 51.5% to 67.7% accuracy) demonstrate that focusing on reasoning quality produces better overall performance.
Critical Analysis
Despite the impressive results, several limitations merit consideration. First, the approach depends heavily on the quality of the initial model's ability to evaluate reasoning. If the model has fundamental misconceptions about valid reasoning patterns, it might reinforce those errors rather than correct them.
The researchers acknowledge this limitation but don't fully address how to ensure the model's evaluation capabilities are sufficiently robust. There's a potential circularity problem - using an AI to evaluate its own reasoning processes assumes the AI already understands good reasoning.
Another concern is that while the method works well for domains with clear evaluation criteria like mathematics, it may be less effective for tasks involving subjective reasoning or value judgments. The chain-of-thought process modeling may be more difficult to evaluate in domains like ethical reasoning or creative writing.
The research also focuses primarily on English-language tasks and mathematical reasoning. Cross-lingual generalization wasn't thoroughly explored, raising questions about how well this approach would work across different languages and cultural contexts.
Finally, the computational efficiency claims deserve scrutiny. While PReSRM may be more efficient than traditional RLHF, it still requires generating multiple reasoning attempts for each problem and running evaluation on each. For very large models or complex problems, this could still present significant computational challenges.
Conclusion
Process-based Self-Rewarding Language Models represent a significant advancement in AI reasoning capabilities. By shifting focus from outcomes to processes, the researchers have demonstrated a more effective approach to improving AI systems' problem-solving abilities.
The success of PReSRM suggests that future AI development should pay greater attention to reasoning transparency and quality. This approach aligns well with human learning, where understanding the "why" behind an answer is often more important than the answer itself.
For the broader field, this research opens promising directions for creating more reliable and reasoning-enhanced AI systems. It also addresses some concerns about AI transparency, as PReSRM naturally produces more interpretable reasoning paths.
The ability to improve mathematical reasoning and planning suggests applications in education, scientific research, and decision support systems. As these techniques mature, we might see AI systems that not only solve problems but help humans understand complex reasoning processes better.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.