

Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length


This is a Plain English Papers summary of a research paper called Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- The paper presents a novel architecture called Megalodon, which enables efficient pretraining and inference of large language models (LLMs) with unlimited context length.
- Megalodon builds upon the Moving Average Equipped Gated Attention (Mega) architecture, which addresses the challenges of long-context learning in LLMs.
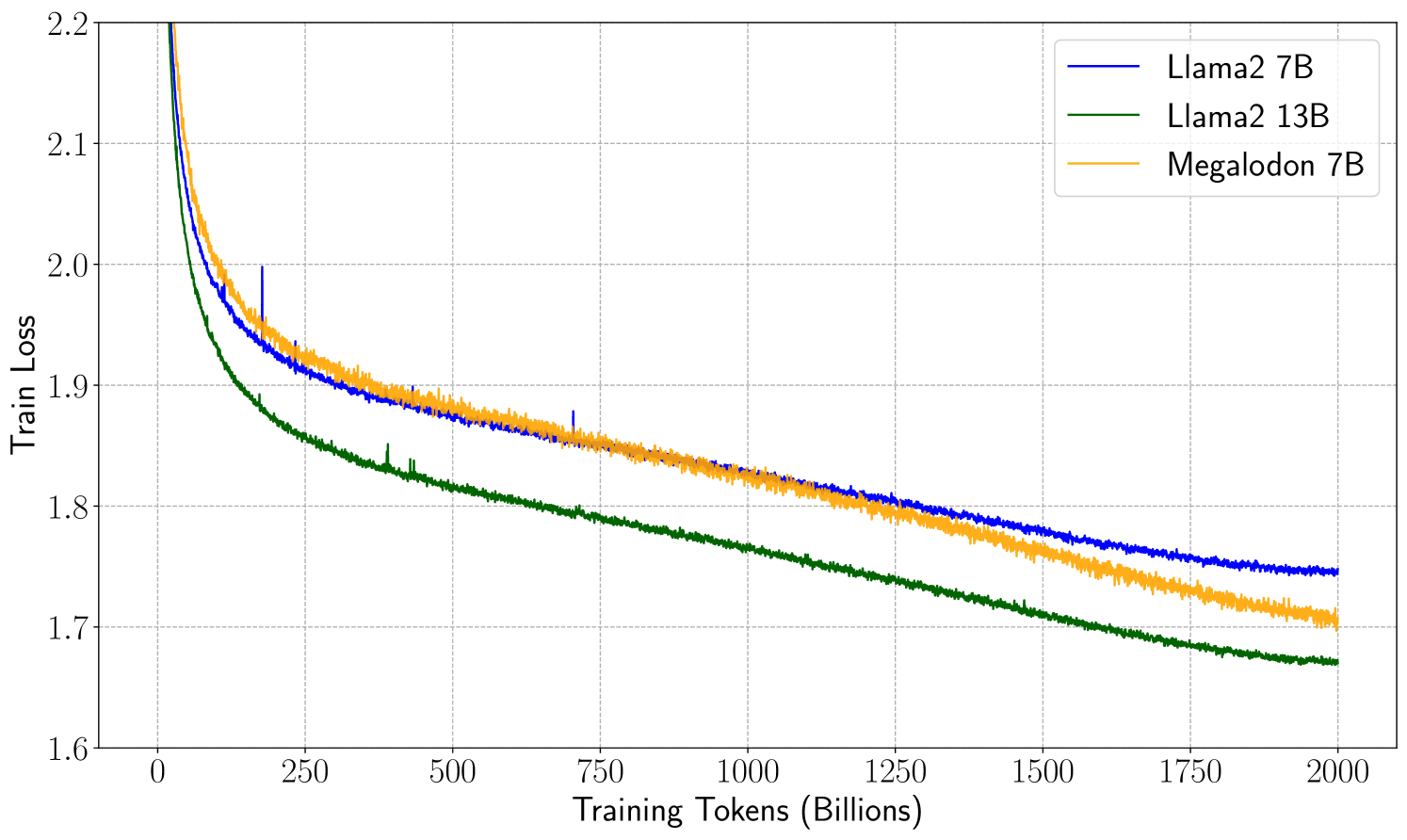
- The authors demonstrate that Megalodon achieves state-of-the-art performance on a range of long-context tasks, while also being more computationally efficient compared to existing approaches.
Plain English Explanation
Megalodon is a new type of large language model (LLM) that can handle very long input texts, unlike traditional LLMs that struggle with long contexts. LLMs are AI systems that are trained on massive amounts of text data to generate human-like language.
The key innovation in Megalodon is its use of a technique called Moving Average Equipped Gated Attention (Mega). This allows the model to efficiently process long input texts without losing important information.
By using Mega, Megalodon can perform better on tasks that require understanding of long-form content, such as summarizing lengthy documents or answering questions about complex topics. Traditional LLMs often have difficulty maintaining context and coherence over long stretches of text.
The authors show that Megalodon outperforms other state-of-the-art models on various long-context benchmarks, while also being more efficient in terms of computational resources. This means Megalodon can be deployed on a wider range of devices and applications, including those with limited processing power.
Technical Explanation
The paper introduces a new architecture called Megalodon, which builds upon the Moving Average Equipped Gated Attention (Mega) mechanism. Mega is designed to enhance the efficiency of large language models (LLMs) during inference by introducing a moving average operation into the attention mechanism.
Megalodon further extends Mega by incorporating techniques to enable efficient pretraining and inference of LLMs with unlimited context length. The key components of Megalodon include:
Mega Attention: The use of Mega attention, which replaces the standard attention mechanism in Transformer-based models. Mega attention maintains a moving average of past attention weights, allowing the model to efficiently aggregate information from long contexts.
Chunked Attention: To handle arbitrarily long input sequences, Megalodon splits the input into smaller chunks and processes them in parallel, with attention computed within and across chunks.
Efficient Pretraining: The authors propose a pretraining strategy that leverages a combination of masked language modeling and a novel cross-attention objective to enable efficient learning of long-range dependencies.
The paper evaluates Megalodon on a range of long-context benchmarks, including LLOCO, LLM2Vec, and others. The results demonstrate that Megalodon achieves state-of-the-art performance on these tasks while being more computationally efficient compared to previous approaches.
Critical Analysis
The paper presents a promising solution to the challenge of processing long input texts in large language models. By leveraging the Mega attention mechanism and other techniques, Megalodon is able to efficiently handle long-context tasks that traditional LLMs struggle with.
However, the paper does not address some potential limitations of the Megalodon approach:
Generalization beyond benchmarks: While Megalodon performs well on the specific long-context benchmarks evaluated, it is unclear how it would generalize to a broader range of real-world applications that may have different characteristics and requirements.
Memory and storage overhead: The paper does not provide a detailed analysis of the memory and storage requirements of Megalodon, which could be a concern for deployment on resource-constrained devices.
Interpretability and explainability: As with many complex neural network architectures, the inner workings of Megalodon may be difficult to interpret and explain, which could limit its adoption in domains that require high levels of transparency.
Further research and evaluation would be needed to address these potential limitations and to more fully understand the strengths and weaknesses of the Megalodon approach.
Conclusion
The Megalodon architecture presented in this paper represents a significant advancement in the field of large language models, enabling efficient pretraining and inference with unlimited context length. By building upon the Mega attention mechanism, Megalodon achieves state-of-the-art performance on long-context benchmarks while being more computationally efficient than previous approaches.
This research has important implications for a wide range of applications that require understanding and generation of long-form text, such as document summarization, question answering, and knowledge-intensive tasks. As language models continue to grow in size and complexity, innovations like Megalodon will be crucial for ensuring these models can be deployed effectively and efficiently in real-world settings.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.