How Sora (actually) works
There’s a lot of disinformation about the most important video model out there. We don’t have to speculate.


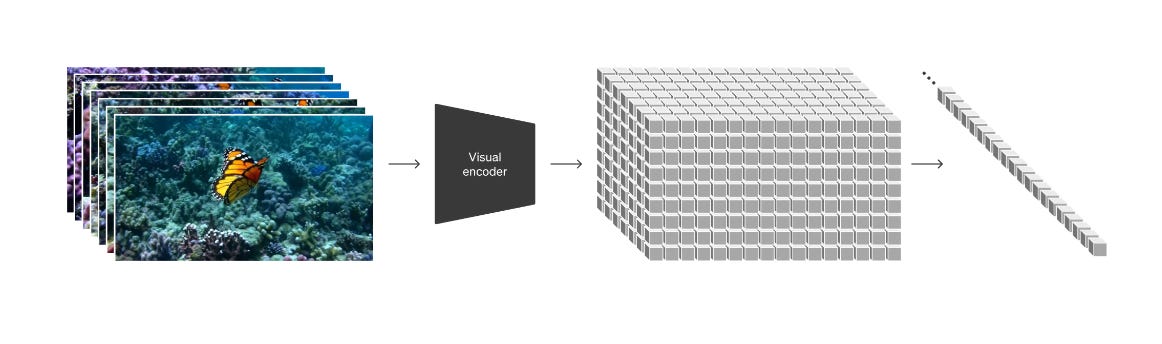
Let's summarize what OpenAI has shared to see how this model actually works.
This week, the team at OpenAI introduce Sora, a large-scale video generation model that displays new capabilities for simulating basic aspects of our physical world. I've been following text-to-video generation for a long time, and I think this model represents a step function increase in terms of quality.
I've also seen a lot of speculation on Reddit and Twitter about how this model works, including some off the wall suggestions (does Sora run inside a game engine called Unreal?). When something this groundbreaking gets released, a lot of people want to appear like they know what's going on, or might even trick themselves into thinking they do know based on subtle clues and artifacts across a super small sample of released videos. The worst example I found of this was Dr. Jim Fan's post claiming that "Sora is a data-driven physics engine," which has been viewed about 4M times on Twitter (It's not a data driven physics engine at all).
Fortunately, OpenAI released a research post explaining their model's architecture, so there's no actual need to speculate if we read what they wrote. In this post, I've done that for you, and I'm going to walk you through what the OpenAI team has provided so we can see how Sora actually works. Let's begin.
Subscribe or follow me on Twitter for more content like this!
Why Sora is a big deal
Creating artificial intelligence that can model, understand, and emulate the intrinsic complexity of the real world has been a profoundly difficult challenge since the inception of the field. Unlike static images, video inherently involves representing change over time, 3D spaces, physical interactions, continuity of objects, and much more. Past video generation models have struggled to handle diverse video durations, resolutions, and camera angles. More importantly, these systems lack the intrinsic "understanding" of physics, causality, and object permanence needed to produce high-fidelity simulations of reality.
The videos released from OpenAI qualitatively show a model that performs better than anything we've seen in these areas. The videos, frankly, look real. For example, a person's head will occlude a sign and then move past it, and the text on the sign will remain as before. Animals will shift wings realistically even when "idle." Petals in the wind will follow the breeze. Most video models fail at this kind of challenge, and the result tends to be some flickery, jittery mess that the viewer's mind has to struggle to make coherent, but Sora doesn't. How?
Technical details on model architecture and training
My first main takeaway when studying the model and available posts is that this work builds upon previous work in language models from OpenAI like their GPT series.
Video Representation
A key innovation the researchers introduced is how Sora represents videos during training. Each frame is divided into many small patches, similar to how words are broken into tokens in large language models like GPT-4. This patch-based approach lets Sora train on videos of widely varying lengths, resolutions, orientations and aspect ratios. The patches extracted from frames are treated exactly the same way regardless of the original shape of the source video.
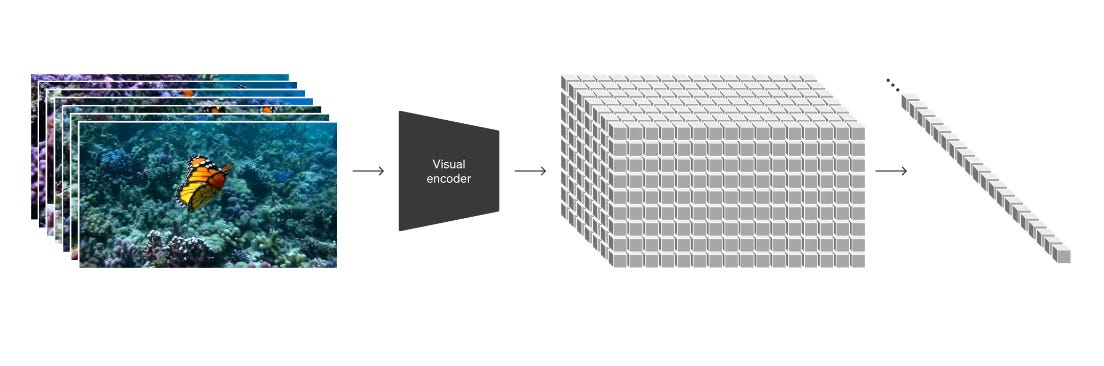
"At a high level, we turn videos into patches by first compressing videos into a lower-dimensional latent space,19 and subsequently decomposing the representation into spacetime patches." - From the OpenAI research post
Model Architecture
Sora uses a transformer architecture closely related to their GPT models to process long sequences of these video patch tokens. Transformers contain spatial-temporal self-attention layers that have shown great benefits for modeling long-range dependencies in sequences like text, audio, and video.
During training, Sora's transformer model takes as input a sequence of video patch tokens from early in the diffusion process and predicts the original "denoised" tokens. By training on millions of diverse videos, Sora slowly learns the patterns and semantics of natural videos frames.

Denoising process graphic from the OpenAI research post
Text Conditioning
Sora is also conditional, meaning it can generate video controllably based on text prompts. The text prompt is embedded and provided as additional context to the model alongside the patches corresponding to the current video frame.
To better connect the textual descriptions to the actual video content, the researchers use highly descriptive captions for each training video generated from a separate caption model. This technique helps Sora adhere more closely to the text prompts.
Inference Process
During inference, Sora starts from pure noise patches and repeatedly denoises them over 50+ diffusion steps until a coherent video emerges. By providing different text prompts, Sora can generate different videos appropriately matched to the caption.
The patch-based representation allows Sora to handle any resolution, duration, and orientation at test time simply by arranging the patches in the desired shape before starting the diffusion process.
Capabilities and Limitations
By scaling up the training data to millions of video clips and using extensive compute resources, the OpenAI team found some pretty interesting emergent behaviors:
Sora is not just text-to-video but can also produce video from input images or other videos.
Sora appears to develop a strong 3D "understanding" of scenes, with characters and objects moving realistically in a continuous manner. This emerges purely from data scale without any explicit 3D modeling or graphics code.
The model displays object permanence, often keeping track of entities and objects even when they temporarily leave the frame or become occluded.
Sora shows the ability to simulate some basic world interactions - for example, a digital painter leaving strokes on a canvas that accurately persist over time.
It can also convincingly generate complex virtual worlds and games, like Minecraft. Sora can simultaneously control an agent moving within this generated environment while rendering the scene.
Video quality, coherence, and adherence to prompts improves substantially with additional compute and data, suggesting further gains from scale.
However, Sora still exhibits significant flaws and limitations:
It frequently struggles to accurately model more complex real-world physical interactions, dynamics, and cause-and-effect relationships. Simple physics and object properties are still challenging. For example, a glass being knocked over and spilling shows the glass melting into the table and liquid jumping through the sides of the glass without any shattering effect.
The model tends to spontaneously generate unexpected objects or entities, especially in crowded or cluttered scenes.
Sora can easily confuse left vs right or the precise sequence of events over time when many actions occur.
Realistic simulation of multiple characters naturally interacting with each other and the environment remains difficult. For example, it will generate a person walking on a treadmill in the wrong direction.
Future Directions
Despite these persistent flaws, Sora hints at the future potential as researchers continue to scale up video generation models. With enough data and compute, video transformers may begin to learn a more intrinsic understanding of real world physics, causality and object permanence. Combined with language comprehension, this could enable new approaches to training AI systems via video-based simulation of worlds.
Sora takes some initial steps towards this goal. While substantially more work is needed to address its many weaknesses, the emergent capabilities it demonstrates highlight the promise of this research direction. Huge transformers trained on massive diverse video datasets may eventually yield AI systems that can intelligently interact with and understand the intrinsic complexity, richness, and depth of our physical environments.
Conclusion
So, contrary to unfounded claims, Sora operates not through game engines or as a "data-driven physics engine" but through a transformer architecture that operates on video "patches" in a way similar to how GPT-4 operates on text tokens. It excels in creating videos that demonstrate an understanding of depth, object permanence, and natural dynamics primarily as an emergent series of scaling properties.
The model's key innovation lies in treating video frames as sequences of patches, similar to word tokens in language models, enabling it to manage diverse video aspects effectively. This method, combined with text-conditioned generation, allows Sora to produce contextually relevant and visually coherent videos from text prompts.
Despite its groundbreaking capabilities, Sora still has limitations, such as modeling complex interactions and maintaining consistency in dynamic scenes. These limitations highlight the need for further research but don't detract from its significant achievements in advancing video generation technology.
I'm hoping that Sora will be released for people to play around with soon, because I can already think of a million cool applications for this kind of technology. Until then, let's stay tuned.
Subscribe or follow me on Twitter for more content like this!