
From Chaos to Clarity with AI-driven Categorization
I’ll show you how I used Replicate’s API to push my AI model categorizer from 22% to 78% accuracy.


Finding a reliable way to select the best model for your AI project is hard. There are thousands of options out there, each optimized for their own task. How do you make sense of the huge selection and pick the right one? Or, how do you make sure you don’t miss out on a crazy new model that might inspire you to create the next great AI product? In either case, you need models to be discoverable and searchable.
That’s why I launched AIModels.fyi — a search engine for AI models. The site offers the ability to sort and pick the best-suited model for your project. Plus, it features a tag system for filtering models based on tasks (such as Text-to-Image or Image-to-Video) for a more focused search.
But this tag feature has become hard to maintain. With the constant addition of new models, manual categorization wasn’t sustainable. So, I decided to use AI to do the work for me. Back in April, I built a basic categorizer to make sure every new model had a tag. However, the accuracy of my prototype solution was poor, and with thousands of users relying on the site each month, I knew I had to step up my game.
In this article, I’ll show you how I used Replicate’s API to push my solution from 22% to 78% accuracy and teach you how to build your own categorizer. We’ll also be using Flan-t5 for this task. Even though it’s not fine-tuned, the open-source Flan-t5 model was developed by Google and is designed to help with classification.
Subscribeor follow me onTwitterfor more content like this!
My old approach to categorizing models
Three months ago, I built a prototype version of the categorizer for the first 300 models on the site. My approach was straightforward but simplistic.
First, I came up with a list of categories (“Text-to-Text,” “Audio-to-Video,” etc.). Then I fetched models from Replicate and pulled in their names and descriptions. I added both the categories and the model data into a GPT-3 prompt and asked GPT-3 to choose a category from the list I provided based on the name and description alone.
My first approach had drawbacks. A description and a name alone are rarely enough to figure out a model’s category. Plus, sometimes the description is blank. Without additional context, it would be difficult for a human to determine the purpose of a model called “train-test.” For a language model such as GPT-3, the best it could do is make a random guess, so most tags were wrong.
I knew I needed to give the language model more context. If I could provide the fields of input and output files, it could make a better call on each model. So, I set out to add the model schemas to my project.
The new approach: Providing model schema and context for better tagging
To get the model schema data, I had to use the Replicate API. The specific endpoint I needed was the ‘Get a model version’ endpoint:
const response = await replicate.models.versions.get(model_owner, model_name, version_id);
The API response contains the property openapi_schema which holds the OpenAPI Schema Objects that describe the inputs and outputs of each model. You can see an example response below:
{
Input: {
type: 'object',
title: 'Input',
required: [ 'prompt' ],
properties: {
n: [Object],
top_p: [Object],
prompt: [Object],
temperature: [Object],
total_tokens: [Object],
repetition_penalty: [Object]
}
},
Output: { type: 'array', items: { type: 'string' }, title: 'Output' },
…}
The names and descriptions of those fields (like “prompt” or “image_height”) held valuable clues about what the models consumed and produced — just what I needed.
Constructing a Node.js Script for Consuming Schema Data
I wrote a Node.js script to put the schema data to work. Before we dive into the code, let me give you a high-level overview of how it works:
We import the necessary modules and environment variables.
We define the categories for classification.
For each model, we fetch data from the Replicate API using a combination of the model’s creator and model name to construct the API URL. We then get the ID of the model’s latest version.
Using this version ID, we make another API request to fetch the model’s version details, including the OpenAPI schema objects.
We then create a prompt for Flan-t5 to generate a category based on the model’s description, an example generation, and the schema data.
If the returned category is valid, it’s used to update the model’s tag in the database.
Now that we understand the process, let’s take a look at the actual code. The first step is simply importing our dependencies. Note that we will be using the replicate npm package, which you can install with npm i replicate.
import { createClient } from "@supabase/supabase-js";
import dotenv from "dotenv";
import Replicate from "replicate";
dotenv.config();
const supabaseUrl = process.env.SUPABASE_URL;
const supabaseKey = process.env.SUPABASE_SERVICE_KEY;
const supabase = createClient(supabaseUrl, supabaseKey);
const replicate = new Replicate({
auth: process.env.REPLICATE_API_KEY,
});
In this section, I also initialize environment variables, and set up clients for the Supabase and Replicate APIs. I’m using Supabase as my DB, but of course, you can choose any provider you like.
Next, I use some code to set up the possible category options. These are permutations of input and output types.
const types = ["Text", "Image", "Audio", "Video"];
const classificationCategories = types.flatMap((fromType) =>
types.map((toType) => `${fromType}-to-${toType}`)
);
This produces options like “Text-to-Text,” “Text-to-Image,” etc. for the language model to use. I found it helps to provide this guidance in the prompt.
Now, it’s time for the fun part: finding untagged models and categorizing them.
export async function classifyModelsAndUpdateTags() {
const { data: models, error: fetchError } = await supabase
.from("replicateModelsData_test")
.select("*")
.filter("tags", "eq", "");
if (fetchError) {
console.error(fetchError);
return;
}
This part of the code fetches models from the Supabase database, specifically, those models whose tags field is empty.
Next, I want to grab the details for each model. It’s a two-part process. First, the loop below goes through each unclassified model and makes an API call to Replicate to fetch the model’s details. It extracts the ID of the model’s latest version and also grabs the “default_example” for the model, which includes an example output in JSON format.
const modelUrl = `https://api.replicate.com/v1/models/${model.creator}/${model.modelName}`;
const modelData = await replicate.models.get(
model.creator,
model.modelName
);
const modelDefaultExample = modelData.default_example;
Then, the section below makes another API call to fetch the model's version details, including the OpenAPI schema objects for input and output.
const modelVersion = await replicate.models.versions.get(
model.creator,
model.modelName,
modelData.latest_version.id
);
const openAPIInputSchema =
modelVersion.openapi_schema.components.schemas.Input.properties;
const openAPIOutputSchema =
modelVersion.openapi_schema.components.schemas.Output;
With this information, we’re ready to feed our prompt to the language model. In this case, the prompt is sent to a Replicate-hosted version of the Flan-t5 model. This prompt is a detailed message containing the model’s description and its input and output schema. The model will use this prompt to generate a classification. Note that I truncated the prompt because it is quite long.
const description = model.description ?? "No description provided.";
const prompt = `Classify the following model into one of the specified categories... Based on what data is going into the model and what is going out of the model...
You may not choose any other categories besides those listed.
Categories: ${classificationCategories.join(", ")}
Description: ${description}
Model: ${model.modelName}
Model Input Schema: ${JSON.stringify(openAPIInputSchema)}
Model Output Schema: ${JSON.stringify(openAPIOutputSchema)}
Model Example Generation: ${JSON.stringify(modelDefaultExample)}
Category: `;
console.log(`Prompt: ${prompt}`); // Log the prompt for debugging purposes
The script then makes a request to the Flan-t5 model to run the classification. I log and store the response, which contains the classification category.
try {
const response = await replicate.run(
"replicate/flan-t5-xl:7a216605843d87f5426a10d2cc6940485a232336ed04d655ef86b91e020e9210",
{
input: {
prompt: `${prompt}`,
},
}
);
console.log(response[0]); // Log the response for debugging
const category = response[0];
If the category returned by the model is valid (i.e., it’s one of the predefined tag categories), the script updates the model’s tags field in the database with this category. If there’s an error during the update, it’s logged. If the category is not valid, a message is logged stating that it’s an invalid category.
if (classificationCategories.includes(category)) {
const { error: updateError } = await supabase
.from("replicateModelsData_test")
.update({ tags: category })
.match({ id: model.id });
if (updateError) {
console.error(`Failed to update model ID ${model.id}:`, updateError);
} else {
console.log(
`Updated model ID ${model.id} with category: ${category}`
);
}
} else {
console.log(`Invalid category: ${category}`);
}
If there’s an error during the classification or database update, it’s caught and logged.
} catch (err) {
console.error(err);
}}
classifyModelsAndUpdateTags();
Finally, the classifyModelsAndUpdateTags function is called to start the classification process! When we call the function, we get an output with a valid category, such as Text-to-Text.
Putting It All Together: An Example
To illustrate how all these components come together, consider the model named “train-test” I mentioned previously, this time with the following schema data:
{
"input": {
"text": {
"type": "string",
"description": "Text to prefix with 'hello '"
}
},
"output": {
"type": "string"
}
}
And the following default_example:
default_example: {
completed_at: '2023-04-06T00:25:08.380806Z',
created_at: '2023-04-06T00:25:03.155760Z',
error: null,
id: 'e43dcexy7jebrkirvwvmzofez4',
input: {
top_k: 50,
top_p: 1,
prompt: 'What is an alpaca?',
decoding: 'top_p',
num_beams: 1,
max_length: 98,
temperature: 0.75,
repetition_penalty: 1
},
…
output: [
'Alpacas', ' are', ' the', ' world’s',
' largest', ' domesticated', ' animal.', …
],…
Our script fetches the model data, prepares the prompt using the description and schema data, and passes it to the Flan-t5 model. The language model then generates the category “Text-to-Text”, which is subsequently used to update the model’s tag in the database. This is the correct category!
Assessing Accuracy
I decided to compare a sample of models’ tags between the old and new methods and give them a score, with the cumulative number correct serving as the accuracy metric.
I chose nine models at random from AIModels.fyi and evaluated them with the old and new approaches. You can see the findings below:
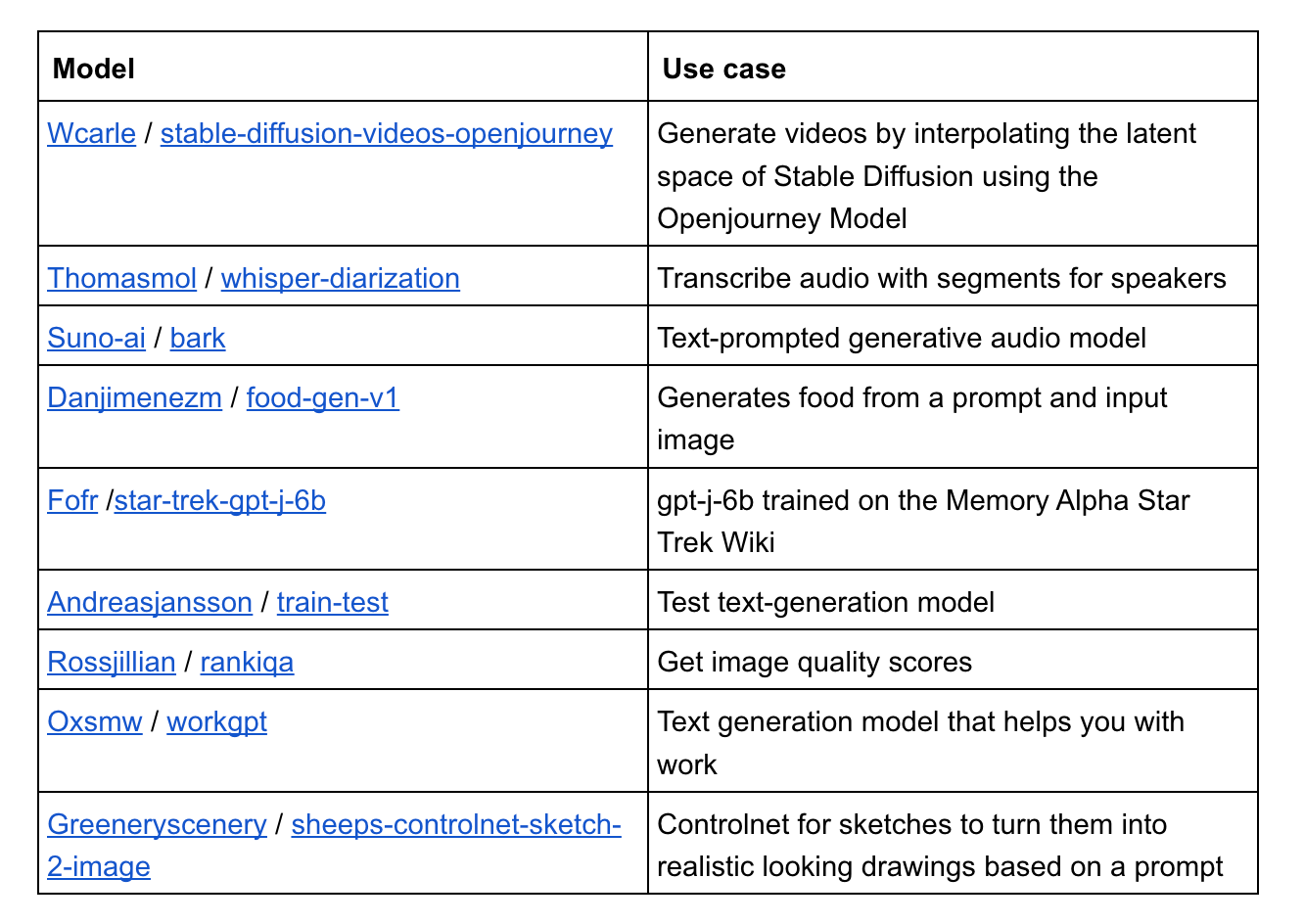
The old method was only 28% correct, whereas the new one was 78% correct — a huge improvement. Clearly, supplying more information made categorization much more accurate.
Taking it Further: Limitations and Future Improvements
No system is perfect, and neither is this one. Even with all the upgrades from the old approach, there are several drawbacks to this implementation. Here are a few:
The classification is currently based solely on the output of the Flan-t5 model. The choice and limitations of this model inherently influence the system’s performance. If the model fails to understand the nuances in the descriptions and schema data, it can result in misclassification.
The system assumes a fixed set of categories. It doesn’t handle categories that weren’t included in the initial list, and it can’t handle multi-modal models. If the models start to include different types of data not currently covered by the system or can handle multiple kinds of data, it will fail to classify these correctly.
Despite these limitations, there are several ways to continue improving the system’s accuracy and make it more robust.
Instead of relying on a single language model, I could create a multi-model voting system. I could use predictions from multiple models and make a voting system from their results to determine the final tag. This can compensate for blind spots in Flan-t5.
Instead of using a fixed list of categories, I could build a system that can learn to identify new categories. This could involve some form of clustering or unsupervised learning to identify new categories and then classify them correctly.
I can incorporate human feedback. For example, I could collect accuracy scores from site visitors. This feedback can then be used to improve the model’s performance.
Conclusion
We’ve come a long way with our automated AI model categorization system, but we’re not done yet. We boosted accuracy from 28% to 78% by adding schema data from Replicate’s API, but, it’s still a work in progress. It’s still not 100% accurate, it relies on a single LLM (which may have blind spots) and it’s not flexible at handling new categories.
We can further improve by making a multi-model voting system and automating category detection. Plus, getting a human-driven feedback loop could be a game-changer.
While we’ve made strides, we’ve still got a ways to go to get this system to its full potential. But, we’ve made big improvements, and that’s something to be proud of. So, now that you’ve seen how it all fits together, I’ve just got one question for you: What will you build next? Thanks for reading!