



This is a Plain English Papers summary of a research paper called Dataset Reset Policy Optimization for RLHF. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper introduces a new method for optimizing the reset policy in Reinforcement Learning from Human Feedback (RLHF) systems.
- The proposed approach, called Dataset Reset Policy Optimization (DRPO), aims to improve the efficiency and robustness of RLHF training by learning a reset policy that can effectively navigate the agent back to a "good" state after it has deviated from the desired behavior.
- The authors demonstrate the effectiveness of DRPO on several benchmark tasks and show that it can outperform existing reset policy optimization methods in terms of sample efficiency and performance.
Plain English Explanation
In Reinforcement Learning from Human Feedback (RLHF), the goal is to train an AI system to behave in a way that aligns with human preferences. This is typically done by rewarding the system when it takes actions that humans consider desirable, and penalizing it when it takes undesirable actions.
However, during the training process, the AI system may sometimes take actions that deviate from the desired behavior and get "stuck" in undesirable states. This can lead to inefficient and unstable training, as the system struggles to recover from these suboptimal states.
The authors of this paper propose a new method called Dataset Reset Policy Optimization (DRPO) to address this issue. The key idea is to train a separate "reset policy" that can quickly navigate the AI system back to a "good" state whenever it starts to veer off course. This reset policy is trained alongside the main policy, using a technique called Trajectory-Oriented Policy Optimization to ensure that it learns to efficiently reset the system.
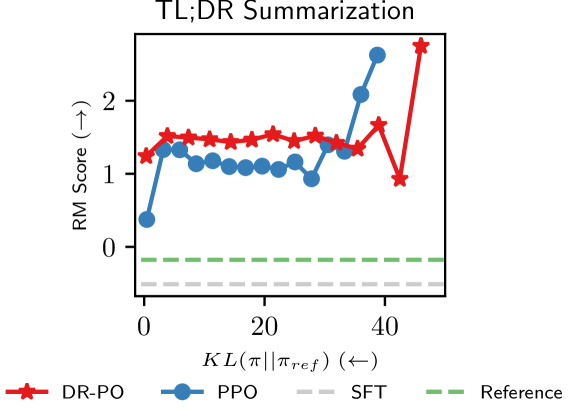
The authors demonstrate that DRPO can significantly improve the sample efficiency and performance of RLHF systems, compared to existing reset policy optimization methods. This is because the reset policy helps the main policy avoid getting stuck in undesirable states, allowing it to explore the state space more effectively and learn a better overall behavior.
Technical Explanation
The key technical components of DRPO are:
Reset Policy: The reset policy is a separate neural network that learns to navigate the agent back to a "good" state whenever it deviates from the desired behavior. This is trained alongside the main policy using a Trajectory-Oriented Policy Optimization approach.
Dataset Reset: During training, the agent's trajectory is periodically "reset" to a state sampled from a dataset of "good" states, using the learned reset policy. This helps the agent avoid getting stuck in undesirable states and explore the state space more effectively.
Reward Shaping: The authors use Robust Preference Optimization to shape the rewards received by the agent, making the training more robust to noise and misalignment in the human feedback.
The authors evaluate DRPO on several benchmark tasks, including Pixel-Wise Reinforcement Learning and CDCL-SAT, and show that it outperforms existing reset policy optimization methods in terms of sample efficiency and final performance.
Critical Analysis
The authors acknowledge several limitations and areas for further research in their paper:
- The effectiveness of DRPO may depend on the quality and diversity of the dataset of "good" states used for resetting the agent's trajectory. More research is needed to understand how to best curate and maintain this dataset.
- The authors only evaluate DRPO on a limited set of benchmark tasks, and it's unclear how well the method would generalize to more complex, real-world problems.
- The training process for the reset policy adds additional computational overhead, which may be a concern for resource-constrained applications.
Additionally, one could raise the following concerns:
- The authors do not provide a detailed analysis of the failure modes or edge cases where DRPO might perform poorly. It would be helpful to have a better understanding of the limitations and potential pitfalls of the method.
- The paper focuses primarily on improving the sample efficiency and performance of RLHF systems, but it does not address the broader question of how to ensure the long-term safety and alignment of these systems as they become more capable.
Overall, while DRPO appears to be a promising approach for improving the robustness and efficiency of RLHF training, further research is needed to fully understand its strengths, weaknesses, and broader implications for the field of AI alignment.
Conclusion
This paper introduces a new method called Dataset Reset Policy Optimization (DRPO) that aims to improve the efficiency and robustness of Reinforcement Learning from Human Feedback (RLHF) systems. By training a separate "reset policy" to navigate the agent back to desirable states, DRPO helps the main policy avoid getting stuck in undesirable states and explore the state space more effectively.
The authors demonstrate the effectiveness of DRPO on several benchmark tasks and show that it can outperform existing reset policy optimization methods. While the paper highlights the potential of DRPO to advance the field of RLHF, it also identifies several limitations and areas for further research, such as the need to better understand the method's generalization capabilities and long-term safety implications.
Overall, this work represents an important contribution to the ongoing efforts to develop safe and effective AI systems that can align with human preferences and values.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.