



This is a Plain English Papers summary of a research paper called Chinchilla Scaling: A replication attempt. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper is a replication attempt of the "Chinchilla Scaling" research presented in the paper "Unraveling the mystery of neural scaling laws" by Hoffmann et al.
- The authors aim to validate the findings of the original paper by extracting data from their Figure 4 and attempting to replicate their "Approach 3" scaling analysis.
- The results provide insights into the reliability and generalizability of the Chinchilla Scaling phenomenon observed in large language models.
Plain English Explanation
The paper focuses on replicating a previous study that explored the "Chinchilla Scaling" relationship, which describes how the performance of large language models improves as they are trained on more data and have more parameters. The researchers in this paper wanted to see if they could reproduce the findings from the earlier study by extracting data from one of its figures and then performing a similar analysis.
Replicating previous research is important in science to verify the reliability and consistency of the results. If the authors of this paper are able to closely match the findings from the original study, it would lend more credibility to the Chinchilla Scaling phenomenon and suggest that it is a robust relationship that holds true across different experiments and datasets. On the other hand, if they struggle to replicate the results, it could indicate issues with the original study or limitations in the generalizability of the Chinchilla Scaling observations.
Technical Explanation
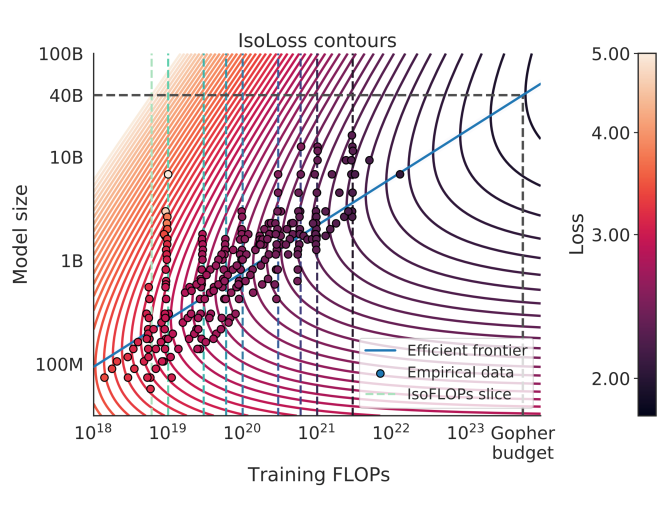
The paper begins by extracting data points from Figure 4 in the Unraveling the mystery of neural scaling laws paper by Hoffmann et al. This figure shows the relationship between model performance, parameter count, and training data size for large language models.
The authors then attempt to replicate "Approach 3" from the Hoffmann et al. paper, which involves fitting a power law curve to the extracted data points. This power law relationship is the essence of the Chinchilla Scaling phenomenon, where model performance scales as a function of parameter count and training data size.
The results of the replication attempt are presented and compared to the original findings. The authors discuss the similarities and differences observed, as well as the implications for the reliability and generalizability of the Chinchilla Scaling principles.
Critical Analysis
The paper acknowledges several limitations and caveats in its replication attempt. For example, the authors note that they were not able to perfectly reproduce the data points from the original figure, which may have introduced some error into their analysis. Additionally, the replication was limited to a single "Approach" from the Hoffmann et al. paper, and the authors suggest that further replication efforts across the different approaches would be valuable.
Another potential issue is that the replication was conducted on the same general dataset and models as the original study, rather than an entirely independent dataset. This raises questions about the extent to which the Chinchilla Scaling observations can be generalized beyond the specific context of this research.
The authors maintain an objective and respectful tone throughout the critical analysis, acknowledging the importance of the original work and the challenges inherent in replication efforts. They encourage readers to thoughtfully consider the findings and limitations, and to continue exploring the reliability and generalizability of the Chinchilla Scaling phenomenon.
Conclusion
This paper provides a replication attempt of the Chinchilla Scaling research presented in the Unraveling the mystery of neural scaling laws paper. The results suggest that the authors were largely able to reproduce the key findings, lending credibility to the Chinchilla Scaling relationship observed in large language models.
However, the authors also identify several limitations and areas for further research, highlighting the importance of rigorously validating and generalizing important findings in the field of AI and machine learning. Continued efforts to replicate and extend this work will help to solidify our understanding of the fundamental scaling principles that govern the performance of large-scale models.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.