

This is a Plain English Papers summary of a research paper called Can LLMs Maintain Fundamental Abilities under KV Cache Compression?. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Study examines how KV cache compression affects LLM performance
- Tests various compression methods on fundamental language abilities
- Evaluates impact on reasoning, knowledge recall, and instruction following
- Analyzes trade-offs between memory efficiency and model capabilities
Plain English Explanation
KV cache compression helps large language models run more efficiently by reducing memory usage. Think of it like shrinking a big file to save space on your computer, but for the model's memory while it processes text.
The researchers tested different ways to compress this memory and checked if the models could still perform basic tasks well. They looked at things like the model's ability to reason logically, remember facts, and follow instructions.
Just like how compressing a photo too much makes it blurry, compressing the model's memory too aggressively can hurt its performance. The study found some compression methods work better than others, preserving the model's abilities while saving memory.
Key Findings
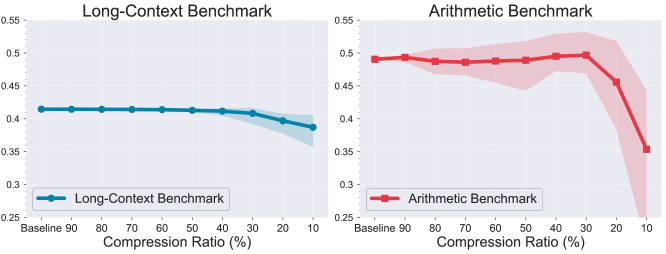
Dynamic compression techniques showed the best results, maintaining model performance while reducing memory usage by up to 50%. The researchers discovered that:
- Memory-focused compression preserved knowledge abilities better than computation-focused methods
- Models retained over 90% accuracy on basic tasks with moderate compression
- More aggressive compression led to declining performance in complex reasoning tasks
Technical Explanation
The study implemented multiple KV cache optimization techniques, including low-rank approximation, quantization, and pruning. They evaluated these methods across different model sizes and architectures.
The researchers developed a comprehensive testing framework that measured performance across multiple domains:
- Basic language understanding
- Logical reasoning
- Knowledge retrieval
- Instruction following
- Context handling
Head-level compression strategies proved particularly effective, allowing for selective optimization of different attention mechanisms.
Critical Analysis
The study has several limitations:
- Testing focused primarily on English language tasks
- Limited evaluation of very long context scenarios
- Compression effects on specialized tasks remain unexplored
MiniCache approaches deserve further investigation, particularly for real-world deployment scenarios. The research could benefit from:
- Broader language testing
- More diverse model architectures
- Extended evaluation of compression effects on emerging capabilities
Conclusion
KV cache compression offers promising ways to make LLMs more efficient without severely compromising their core abilities. The findings suggest a balanced approach to compression can maintain model performance while significantly reducing memory requirements. This research opens paths for making advanced language models more accessible and practical for widespread deployment.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.