When an LLM is apprehensive about its answers -- and when its uncertainty is justified


This is a Plain English Papers summary of a research paper called When an LLM is apprehensive about its answers -- and when its uncertainty is justified. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- LLMs express uncertainty in their responses, sometimes confessing ignorance
- Researchers analyzed when LLMs express uncertainty and if it matches actual accuracy
- The study used Claude, GPT-4, Llama-2, and Mistral models on multiple-choice questions
- Found uncertainty expressions correlate with answer correctness
- Created a new dataset and evaluation framework for LLM uncertainty
- Discovered that larger models are better at calibrating their uncertainty
Plain English Explanation
When you ask a large language model (LLM) like ChatGPT a question, sometimes it hesitates or expresses doubt about its answer. This paper investigates whether an LLM's expressions of uncertainty actually match its performance.
Imagine asking a friend a trivia question. Sometimes they'll confidently give an answer, while other times they might say "I'm not sure, but I think it's X." This research looks at when AI systems express similar uncertainty and whether that uncertainty is justified.
The researchers asked different AI systems multiple-choice questions and analyzed their responses. They found that when an LLM says it's uncertain about an answer, it's more likely to be wrong. When it expresses confidence, it's more likely to be right. This relationship between expressed uncertainty and accuracy is called calibration.
The study revealed that more advanced LLMs like GPT-4 and Claude are better at knowing when they don't know something compared to smaller models. This is important because a system that knows its limitations is more trustworthy than one that confidently gives wrong answers.
Key Findings
- LLMs naturally express uncertainty through phrases like "I'm not entirely sure" or "I might be wrong"
- There's a strong correlation between an LLM's expressed uncertainty and the correctness of its answers
- Larger, more capable models (GPT-4, Claude) show better uncertainty calibration than smaller models (Llama-2, Mistral)
- Models perform consistently across different domains (science, medicine, humanities) when expressing uncertainty
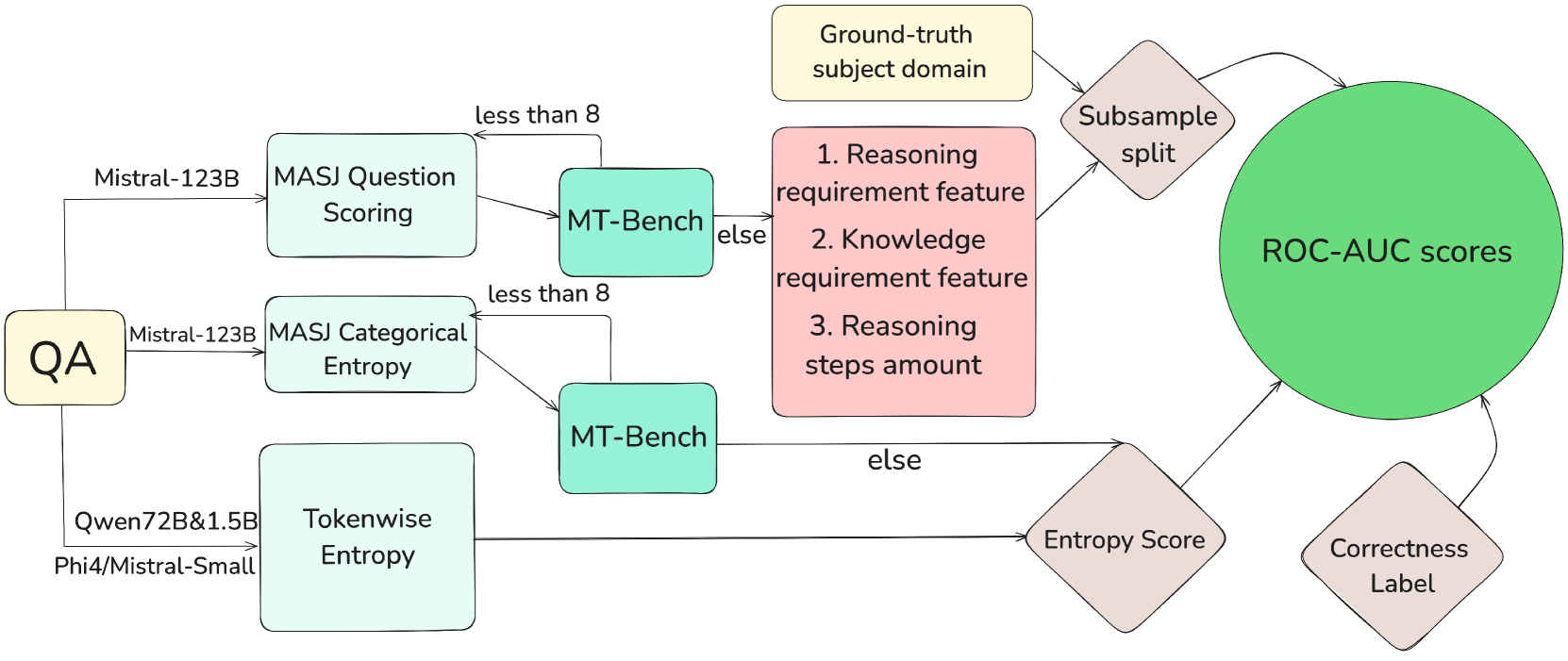
- The researchers created MUQ (Model Uncertainty Quantification), a new dataset of 12,000 multiple-choice questions to evaluate LLM uncertainty
- Uncertainty expressions were classified into three levels: certain, somewhat uncertain, and very uncertain
- Models that offer explanations with their answers show better alignment between uncertainty and correctness
Technical Explanation
The researchers developed a systematic framework for evaluating how well LLMs can assess their own uncertainty. They focused on multiple-choice questions with unambiguous answers, allowing them to clearly measure when a model's uncertainty is justified.
The study examined four models: Claude-2, GPT-4, Llama-2-70B, and Mistral-7B. To automate the analysis, they created a classifier that categorizes model responses into three uncertainty levels based on linguistic markers. This approach avoids asking models to directly rate their confidence, which can lead to unreliable self-assessments.
Their MUQ dataset contains questions from established benchmarks like MMLU, MedQA, and TruthfulQA. The questions span domains including medicine, science, humanities, and ethics. This comprehensive approach helps evaluate whether models can recognize when they're likely to make errors across different types of knowledge.
The technical analysis shows that larger models not only perform better on answering questions correctly but also demonstrate superior uncertainty calibration. This suggests that the ability to recognize knowledge limitations emerges as models become more capable overall.
The researchers also examined explanatory reasoning, finding that models that explain their answers tend to show improved uncertainty calibration. This indicates that generating explanations helps models better assess their own knowledge limitations.
Critical Analysis
While the findings are promising, several limitations should be considered. First, the study focuses exclusively on multiple-choice questions, which represents a simplified form of knowledge assessment compared to open-ended questions that might better reflect real-world use.
The classification of uncertainty expressions into just three levels may oversimplify the nuanced ways models express doubt. Human uncertainty exists on a spectrum, and reducing LLM expressions to three categories might miss important variations in confidence levels.
Additionally, the research doesn't fully address potential differences between uncertainty due to knowledge gaps versus uncertainty arising from ambiguous questions. In real-world contexts, questions often have inherent ambiguity that would justifiably lead to expressed uncertainty regardless of model knowledge.
The paper also doesn't explore how uncertainty calibration might vary across different model versions or fine-tuning approaches. As models evolve rapidly, understanding how these capabilities change across iterations would provide valuable insights for developers and users.
Finally, there's limited discussion about how these findings might translate to practical applications. While knowing that a model correctly expresses uncertainty is valuable, the paper doesn't fully address how users might leverage this information when interacting with AI systems.
Conclusion
This research provides important insights into how well LLMs can recognize and communicate their own limitations. When an AI system expresses uncertainty, that uncertainty is often justified by actual performance limitations - especially in more advanced models.
The strong correlation between expressed uncertainty and answer correctness suggests that users can potentially trust these signals from AI systems, particularly from more capable models like GPT-4 and Claude. This capability could be crucial for developing more trustworthy AI systems that don't mislead users with false confidence.
The findings also indicate that model uncertainty abilities improve alongside general capabilities, suggesting that continued advances in LLM development will likely enhance these important metacognitive skills. The better a model becomes at answering questions correctly, the better it seems to become at recognizing when it might be wrong.
As AI systems become more integrated into decision-making processes, the ability to properly express uncertainty becomes increasingly important. This research establishes valuable metrics and evaluation methods that can help guide the development of more honest, self-aware AI systems that know when to say "I'm not sure" - and mean it.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.