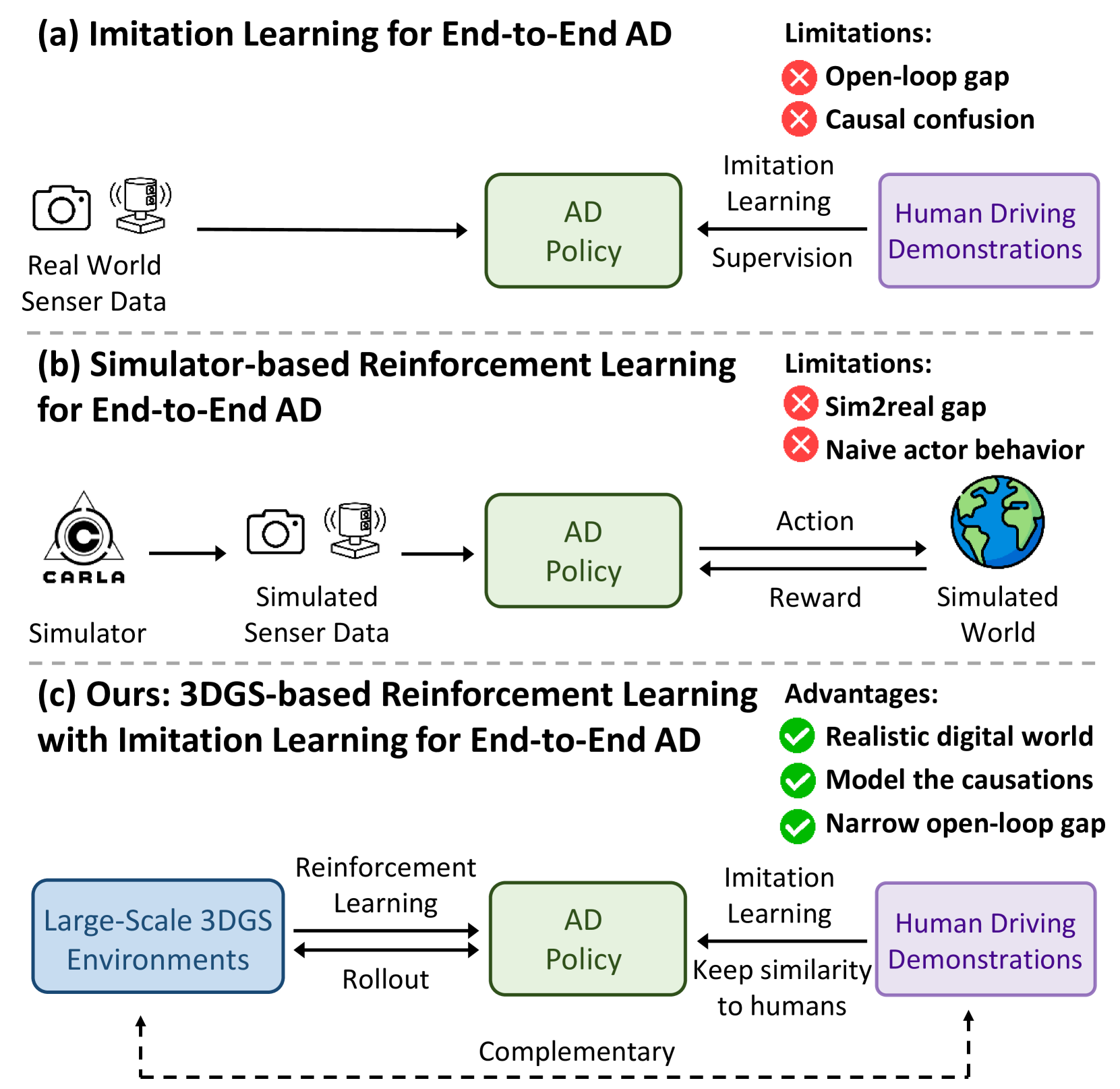
RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning


This is a Plain English Papers summary of a research paper called RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Introduces RAD - a novel end-to-end autonomous driving system using reinforcement learning
- Utilizes 3D Gaussian Splatting for efficient scene representation
- Achieves state-of-the-art performance in complex driving scenarios
- Trains on large-scale synthetic data with over 100 million frames
- Demonstrates robust generalization to real-world conditions
Plain English Explanation
RAD's autonomous driving system works like a human learning to drive through practice and experience. Instead of being explicitly programmed with rules, the system learns by trying different actions and receiving feedback on their outcomes.
The system uses a clever way to understand its surroundings called 3D Gaussian Splatting, which creates efficient 3D representations of the environment. Think of it like taking a complex 3D world and breaking it down into simple, manageable chunks that a computer can process quickly.
The training happens in a virtual environment where the system can safely make mistakes and learn from them. It's similar to how pilots train in flight simulators before flying real planes. The system practices driving through millions of different scenarios, learning how to handle everything from normal traffic to challenging situations.
Key Findings
The end-to-end driving system demonstrated remarkable capabilities:
The system successfully learned to navigate complex urban environments, handling multiple lanes, intersections, and varying weather conditions. It showed particular strength in:
- Smooth navigation through dense traffic
- Appropriate speed adjustment based on conditions
- Proper lane changing and merging behavior
- Reliable obstacle avoidance
- Consistent performance across different lighting and weather conditions
Technical Explanation
The reinforcement learning approach uses a policy network that takes in processed sensor data and outputs driving commands. The system's architecture combines:
- A 3D Gaussian Splatting module for scene representation
- A transformer-based policy network for decision making
- A reward function that balances safety, comfort, and efficiency
The training process involved over 100 million frames of synthetic data, with careful attention to domain randomization to ensure real-world transferability. The scaling approach proved crucial for achieving robust performance.
Critical Analysis
While the results are impressive, several limitations deserve attention:
- The system's performance in extreme weather conditions remains untested
- Real-world validation is limited compared to simulation testing
- The computational requirements for training are substantial
- Edge cases and rare scenarios may not be adequately represented
The generative learning approach could benefit from more extensive real-world testing and validation in diverse geographic locations.
Conclusion
RAD represents a significant step forward in autonomous driving technology. Its success in combining reinforcement learning with efficient 3D scene representation opens new possibilities for scalable autonomous systems. The approach demonstrates that end-to-end learning can achieve sophisticated driving behaviors while maintaining safety and reliability.
The potential impact extends beyond driving to other autonomous systems requiring complex decision-making in dynamic environments. Future work will likely focus on reducing computational requirements and expanding real-world validation.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.