

This is a Plain English Papers summary of a research paper called Lessons From Red Teaming 100 Generative AI Products. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Analysis of red team testing on 100 generative AI products
- Focus on identifying security vulnerabilities and safety risks
- Development of threat model taxonomy and testing methodology
- Key findings on common attack vectors and defense strategies
- Recommendations for improving AI system security
Plain English Explanation
Red teaming is like having professional hackers test your security system to find weaknesses before real attackers do. This research tested 100 different AI products to see how they could be misused or attacked.
The team created a comprehensive guide to AI security threats by categorizing different types of attacks. They found that many AI systems have similar weak points, especially when it comes to generating harmful content or revealing private information.
Just like how a bank might test its vault security, these researchers systematically probed AI systems to find potential problems. They discovered that even well-protected AI systems often have unexpected vulnerabilities, similar to finding a back door that nobody knew existed.
Key Findings
The research revealed several critical vulnerabilities across tested systems:
- Most AI products could be manipulated to bypass safety filters
- Systems frequently exposed sensitive information when prompted cleverly
- Many products showed consistent weaknesses against specific attack patterns
- Red teaming effectiveness varied significantly based on testing approach
Technical Explanation
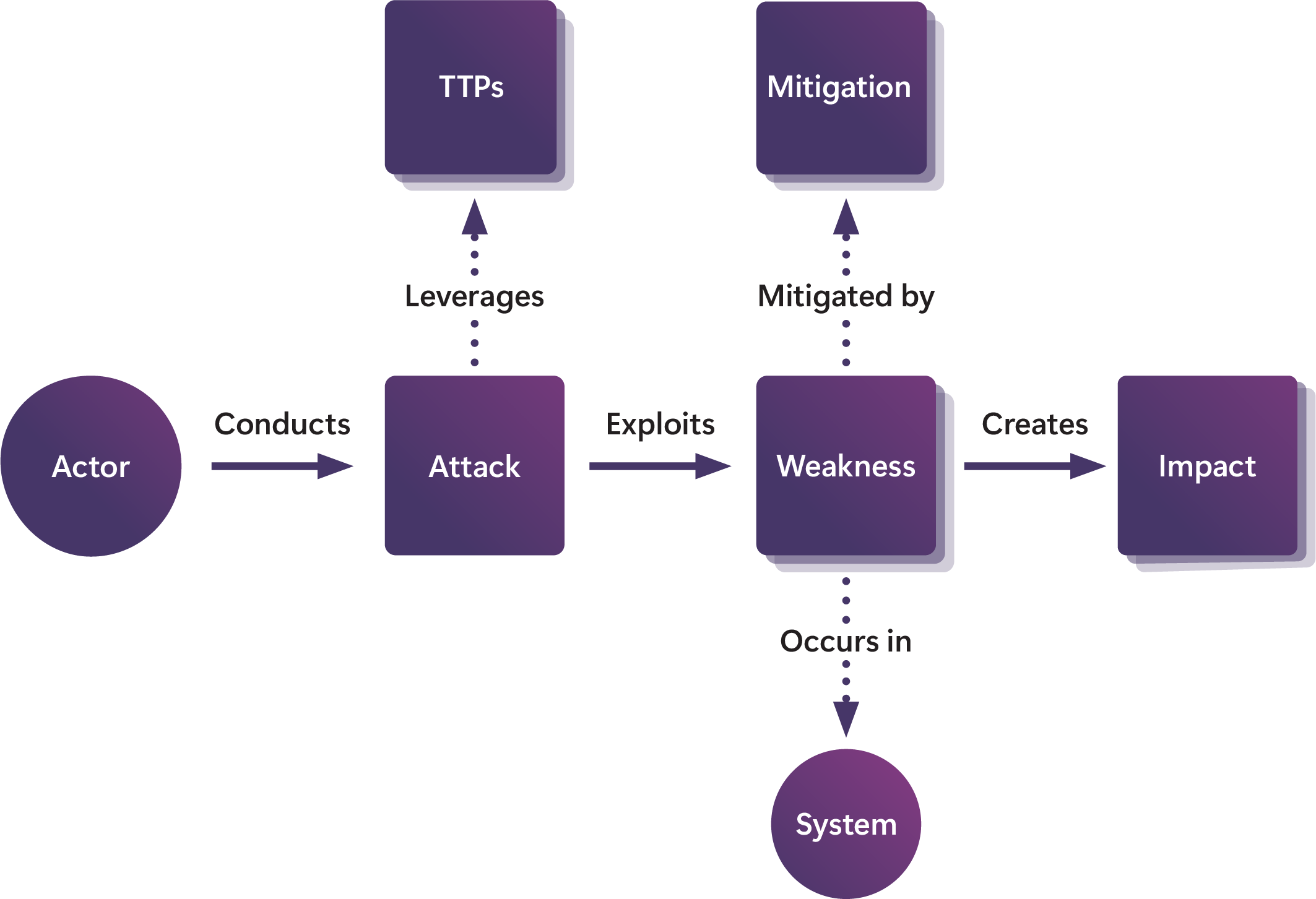
The study implemented a structured testing methodology across multiple AI products. The research team developed a threat model ontology that categorizes potential attacks into distinct categories including prompt injection, data extraction, and system manipulation.
Testing procedures involved systematic probing of each system using standardized attack vectors. The human factor in AI testing proved crucial, as creative approaches often revealed vulnerabilities that automated testing missed.
The researchers documented successful attack patterns and defense mechanisms, creating a comprehensive database of AI system vulnerabilities and potential countermeasures.
Critical Analysis
Several limitations affect the study's conclusions:
- Testing focused primarily on language models, leaving other AI types unexplored
- Rapid AI development may make some findings obsolete quickly
- Limited access to some commercial systems restricted testing depth
- The practitioner's perspective on challenges suggests more complex issues exist
Conclusion
This research provides crucial insights into AI system vulnerabilities and establishes a foundation for improved security practices. The findings highlight the need for continuous security testing and robust defense mechanisms in AI development.
The work emphasizes that lessons from red teaming should inform future AI development practices. The research suggests that systematic security testing should become standard practice in AI system deployment.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.